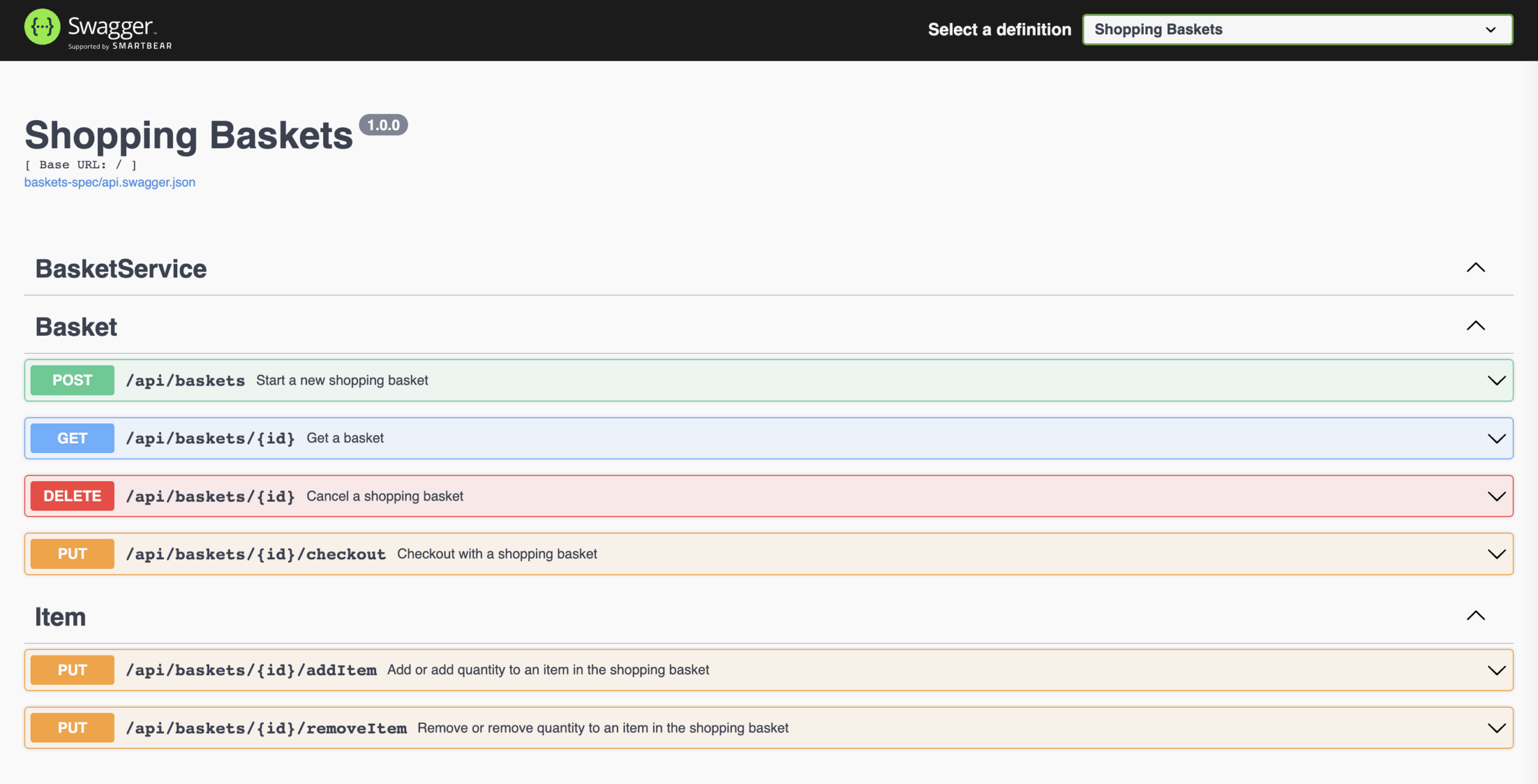
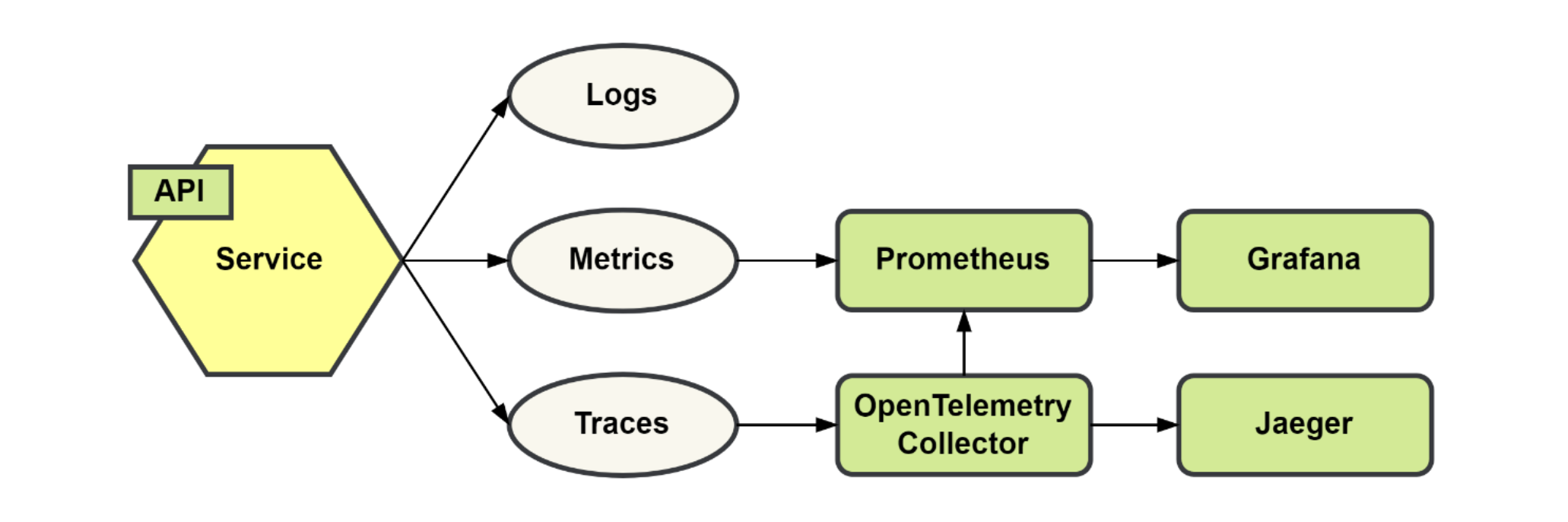
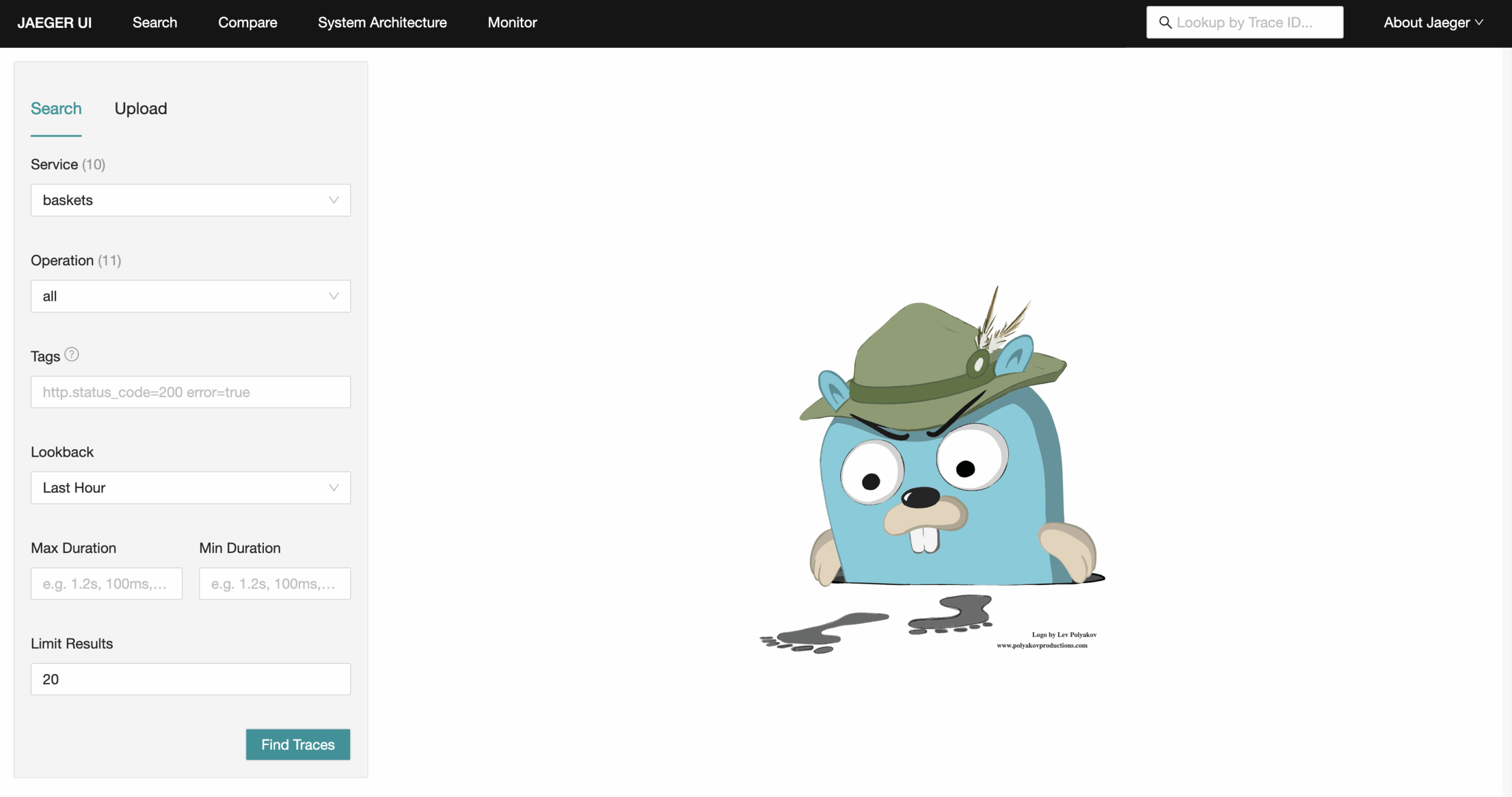
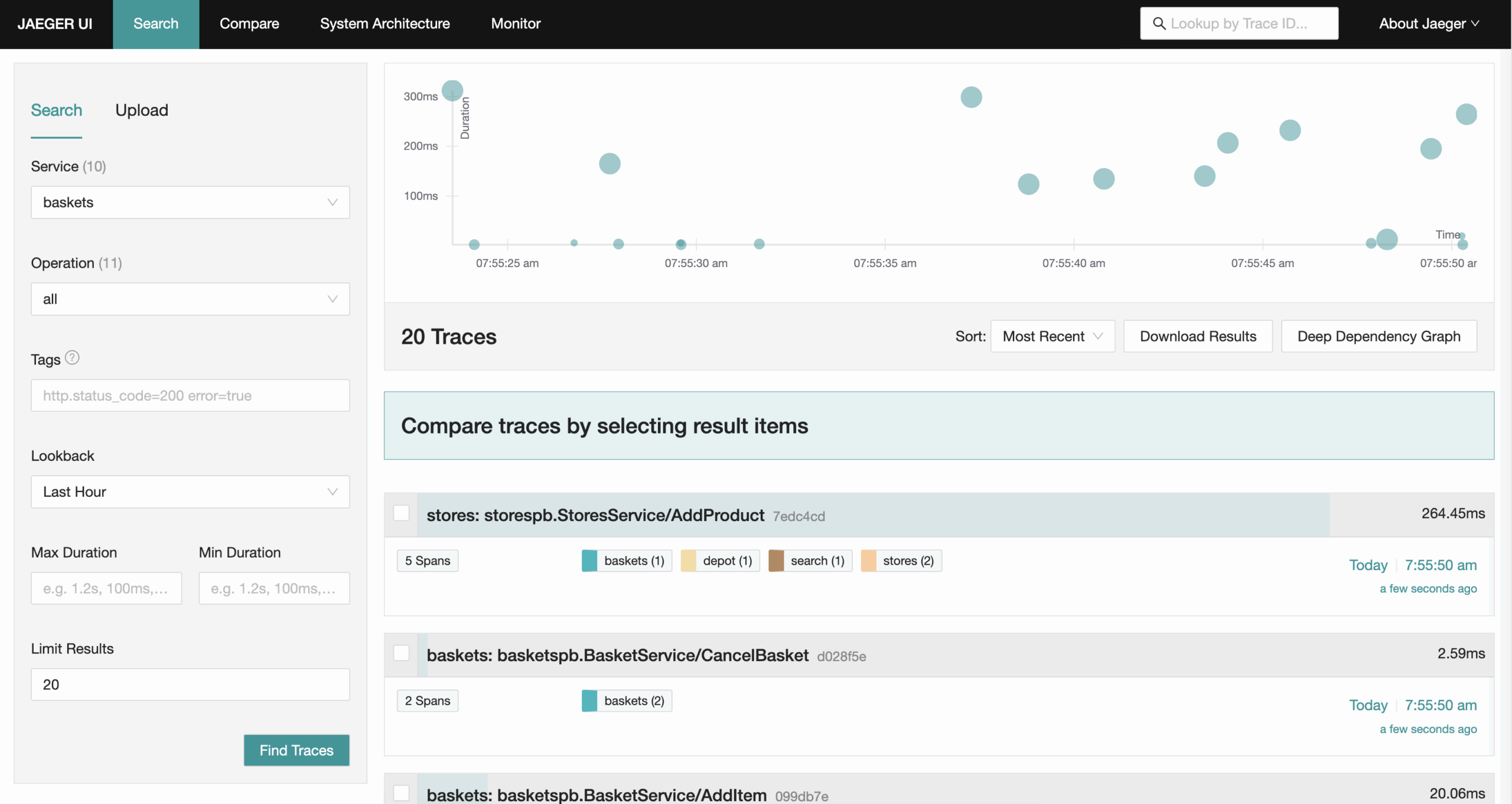
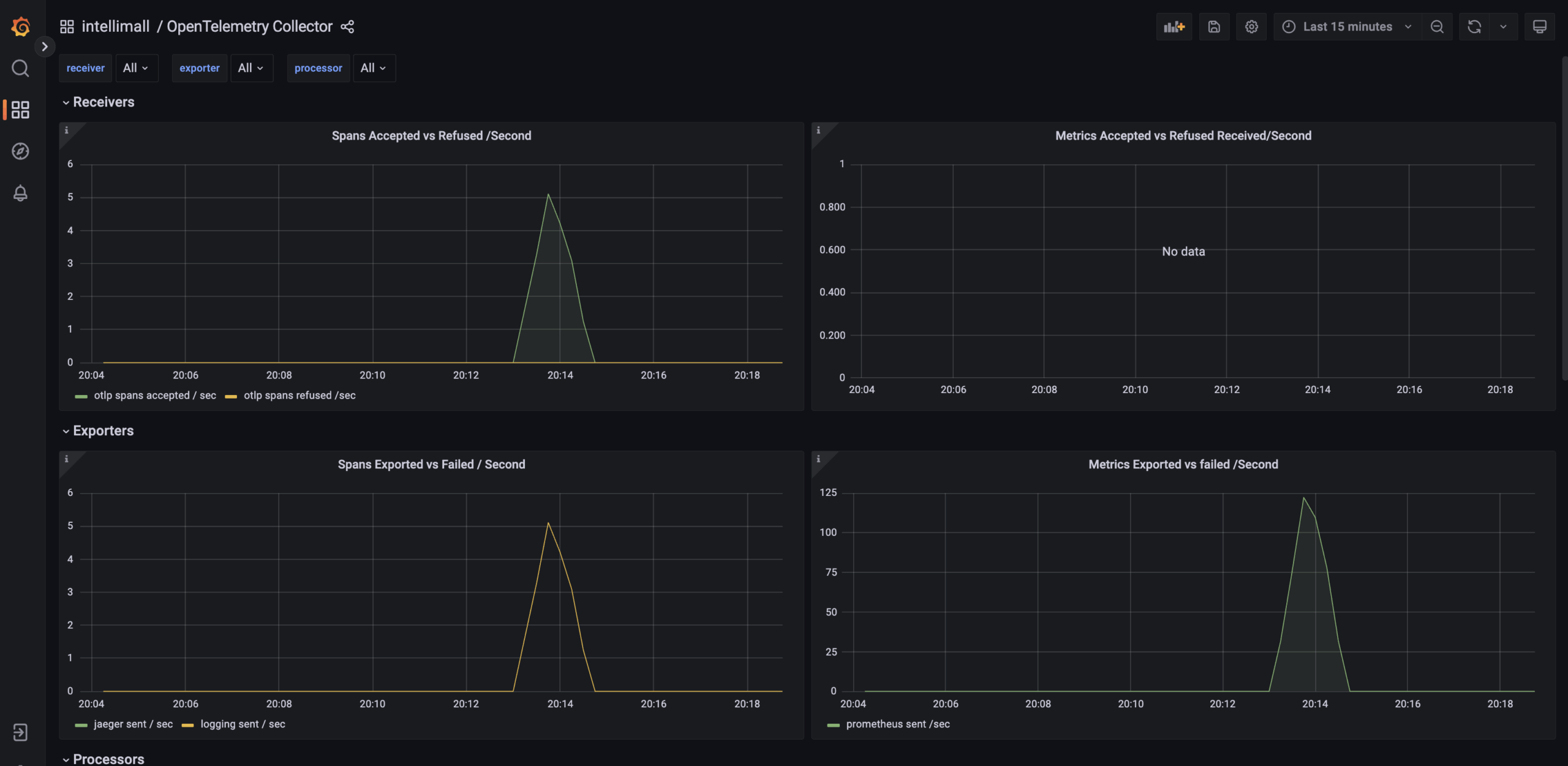
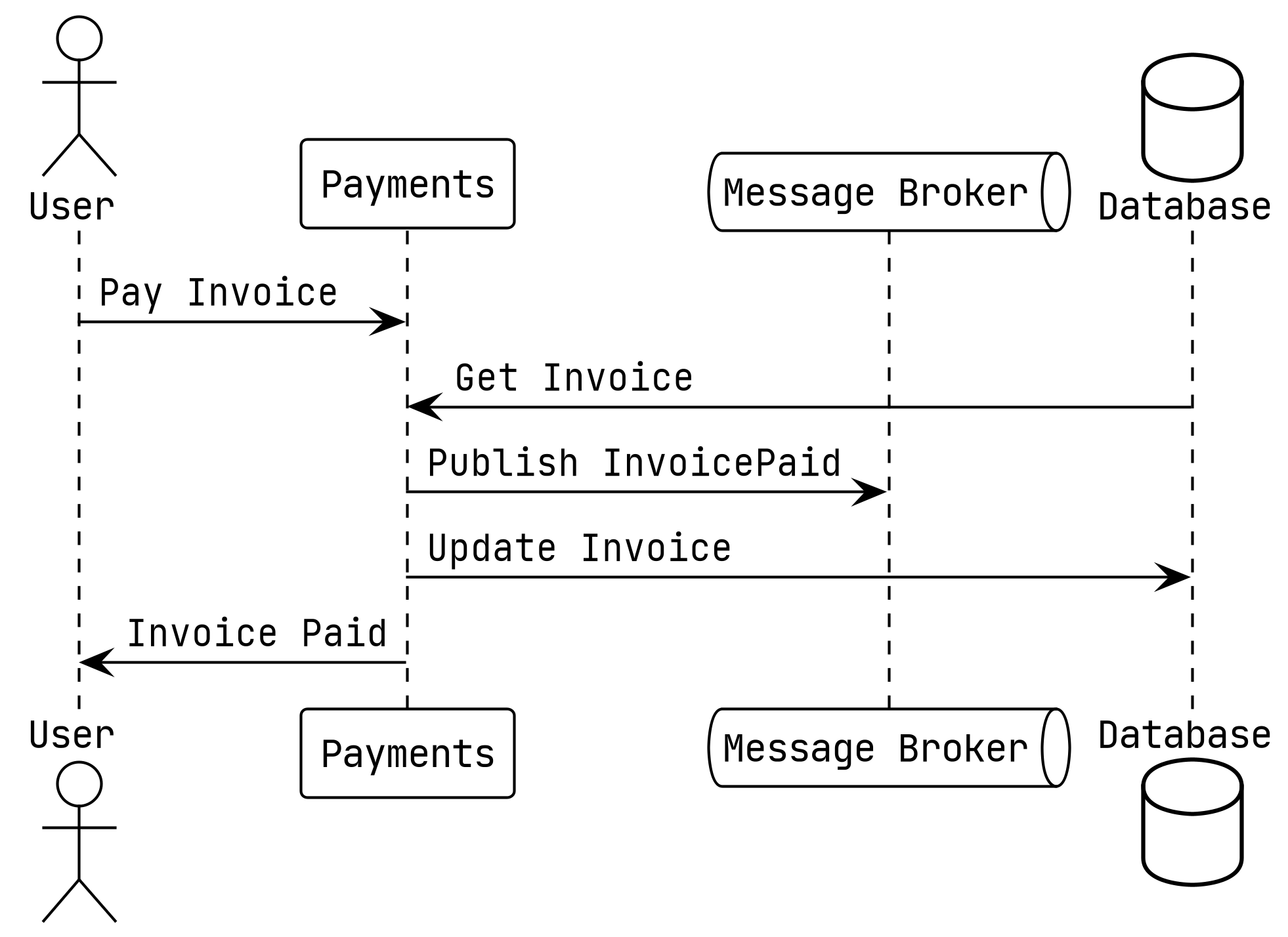
Dockerized PHP development stack: Nginx, Apache2, PHP-FPM, HHVM, MySQL, MariaDB, PostgreSQL, MongoDB, Neo4j, RethinkDB, Minio, Redis, Memcached, Beanstalkd, RabbitMQ and Elasticsearch.

Dockbox allows you to containerize your PHP application allowing you to build a local development environment using Docker.
Dockbox gives you everything you need for developing PHP applications locally. It provides an OS-agnostic and virtualized alternative to MNPP stack. Dockbox tries to keep download file size to a minimum by utilizing official docker images.
# Clone dockbox inside your PHP project (Laravel):
git clone https://github.com/MobileSnapp/dockbox.git
# Run your containers:
docker-compose up -d nginx mysql redis rabbitmq elasticsearch
# (For Laravel) Open your project’s .env file and set the following:
DB_HOST=dockbox-mysql
REDIS_HOST=dockbox-redis
QUEUE_HOST=dockbox-rabbitmq
# Open your browser and visit localhost: http://localhost.
- Official and rated Docker images
- Every software runs as a separate container
- Easy to apply configurations inside containers.
- Faster image and container builds.
- Pre-configured NGINX for Laravel. (Setup for Symfony, Phalcon and Silex coming soon…)
- MySQL
- MariaDB
- PostgreSQL
- MongoDB
- Neo4j
- RethinkDB
- Minio
- OrientDB
- Redis
- Memcached
- Apache2
- Nginx
- PHP (included in Apache2 container)
- PHP-FPM (included in Nginx container)
- HHVM
- Beanstalkd (includes console)
- RabbitMQ (includes console)
- PhpMyAdmin (for MySQL/MariaDB)
- PgAdmin (for PostgreSQL)
- Elasticsearch
- Node
- Mailhog
- Selenium Grid
- Docker Registry
- Docker Engine
- Docker Compose
- Docker Machine (Mac and Windows only)
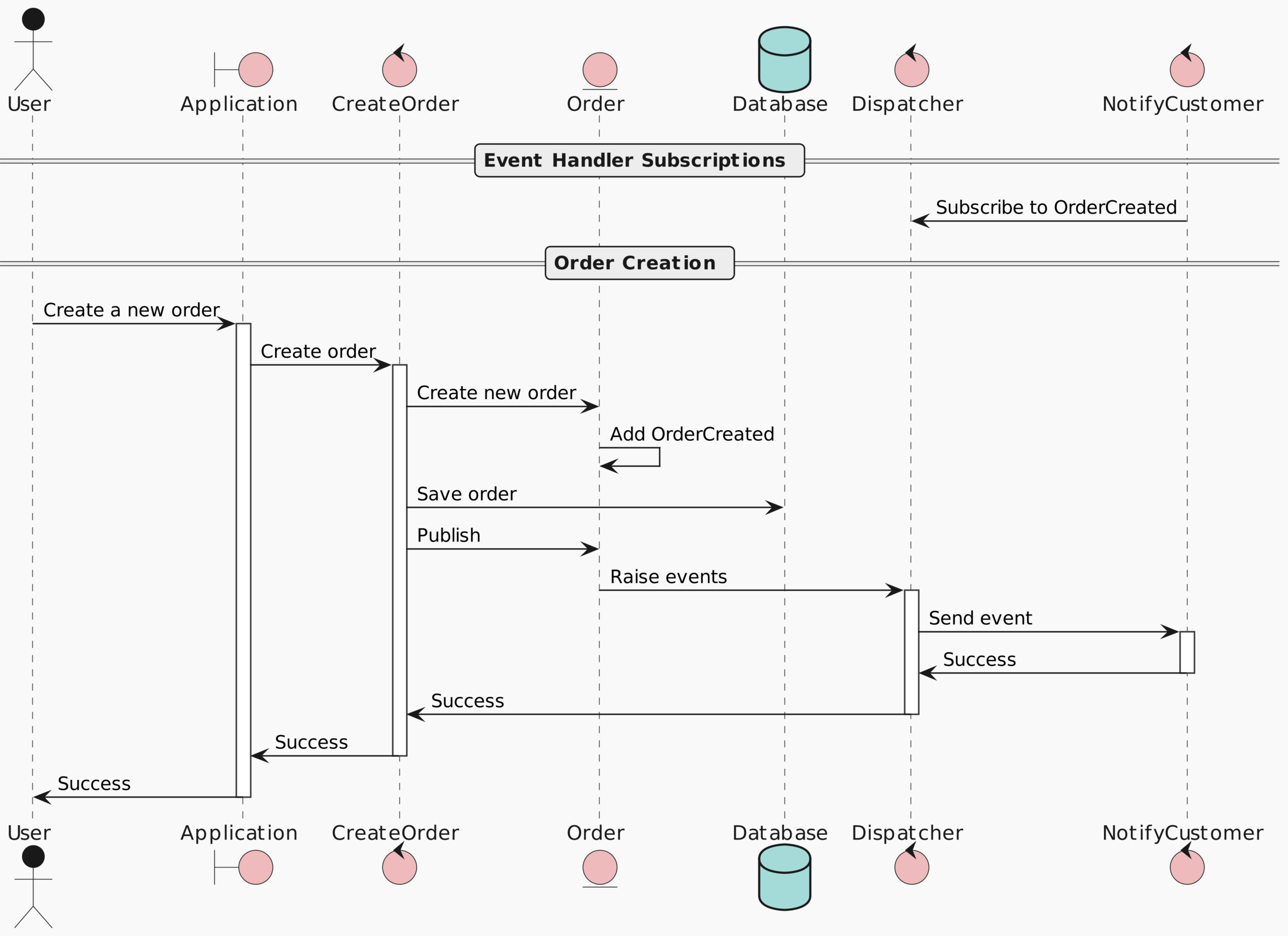
Dockbox currently follows generic ‘Zend/Laravel/Lumen’ folder structure assuming that the hosting files are loacated under ‘public’ directory. Support for other framework (Symfony, Phalcon, Silex) coming soon.
Web root folder: '/var/www/site/public'
For Apache, default web configuration setup is available as dockbox default. Uncomment custom configuration in apache/Dockerfile for custom/generic (Zend/Laravel/Lumen) configuration.
Granting permisssion to database users
'GRANT ALL PRIVILEGES ON * . * TO 'sitedb_user'@'localhost';'
More details: DigitalOcean
'ALTER USER sitedb_user WITH SUPERUSER;'
More details: DigitalOcean
- Clone dockbox inside your PHP project (Zend/Laravel/Lumen):
git clone https://github.com/MobileSnapp/dockbox.git
- Your folder structure should look like this:
+ php-project
+ dockbox
- Build the enviroment and run it using docker-compose: Run NGINX (web server) and MySQL (database engine) to host a PHP web project:
docker-compose up -d nginx mysql
You can select your own combination of containers form the list below:
nginx (PHP_FPM included), apache, hhvm, mariadb, mysql, postgres, mongo, minio, rethinkdb, orientdb, redis, memcached, rabbitmq, beanstalkd, node, elasticsearch, neo4j, mailhog, selenium grid and more…!
Note: The data container will run automatically in most of the cases, so no need to specify them in the up command. It will setup the project folder and stop.
Dockbox is setup to run management console with the following containers:
mariadb, mysql, progres, rabbitmq, beanstalkd
Comment ‘links’ section in ‘docker-compose’ file to detach the management console.
- Enter apache/nginx container, to execute commands like (Composer, PHPUnit …): For apache:
docker-compose exec dockbox-apache bash
For nginx:
docker-compose exec dockbox-nginx bash
Alternatively, for Windows PowerShell users: execute the following command to enter any running container:
docker exec -it {workspace-container-id} bash
- Enter the node container, to execute commands like (Artisan, Gulp, …):
docker-compose exec dockbox-node bash
-
Update your project configurations: DB_HOST=dockbox-mysql REDIS_HOST=dockbox-redis QUEUE_HOST=dockbox-rabbitmq
-
Open your browser and visit localhost: http://localhost.
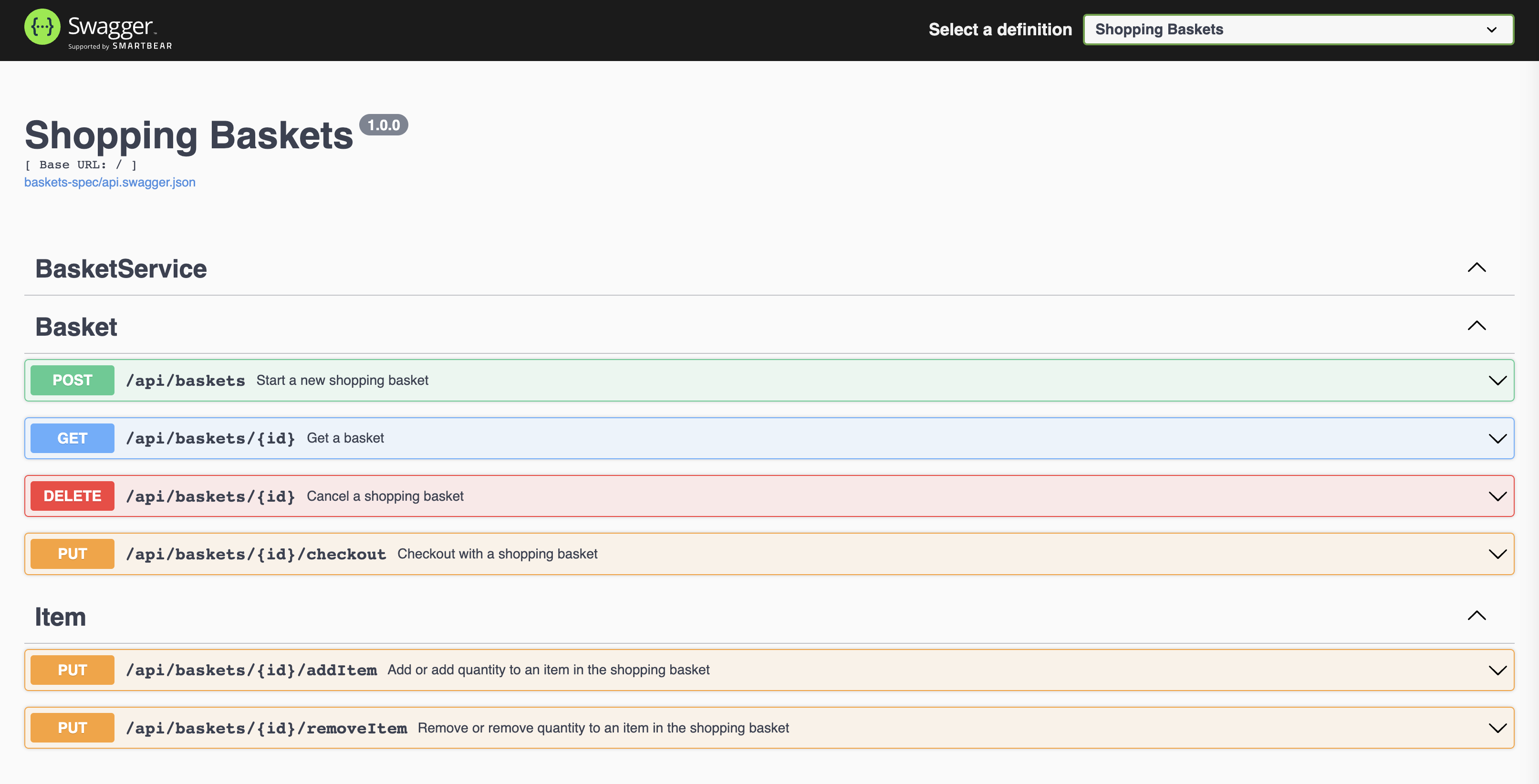
| Container | Command |
|---|---|
| apache | docker-compose up -d apache |
| nginx | docker-compose up -d nginx |
| hhvm | docker-compose up -d hhvm |
| mariadb | docker-compose up -d mariadb |
| mysql | docker-compose up -d mysql |
| postgres | docker-compose up -d postgres |
| mongo | docker-compose up -d mongo |
| minio | docker-compose up -d minio |
| rethinkdb | docker-compose up -d rethinkdb |
| orientdb | docker-compose up -d orientdb |
| redis | docker-compose up -d redis |
| memcached | docker-compose up -d memcached |
| rabbitmq | docker-compose up -d rabbitmq |
| beanstalkd | docker-compose up -d beanstalkd |
| node | docker-compose up -d node |
| elasticsearch | docker-compose up -d elasticsearch |
| neo4j | docker-compose up -d neo4j |
| mailhog | docker-compose up -d mailhog |
| docker registry | docker-compose up -d docker-registry |
| selenium chrome node | docker-compose up -d selenium-chrome-node |
| selenium firefox node | docker-compose up -d selenium-firefox-node |
Note: Selenium chrome/firefox node will bring up Selenium Hub container and attach to Selenium Hub.
- Copyright 2017 MobileSnapp Inc.
- Distributed under the MIT License (hereby included)
 https://github.com/MobileSnapp/dockbox
https://github.com/MobileSnapp/dockbox